
แม้เทคโนโลยีจะก้าวหน้า แต่การป้อนข้อมูลด้วยมือยังคงเป็นวิธีที่ใช้กันอย่างแพร่หลายในองค์กรธุรกิจ โดยเฉพาะธุรกิจ B2B ซึ่งมีถึง 48% ที่ยังคงใช้วิธีนี้ [1] ปฏิเสธไม่ได้ว่า ปัญหาสำคัญของกระบวนการนี้คือความเสี่ยงต่อข้อผิดพลาดของมนุษย์ (Human error) ซึ่งตามรายงานของ Gartner ทำให้องค์กรสูญเสียเงินโดยเฉลี่ยถึง 15 ล้านดอลลาร์สหรัฐต่อปี หรือราว ๆ 500 ล้านบาทไทย [2]
นอกจากนี้ การที่พนักงานต้องมาคีย์เอกสารด้วยตัวเองทีละแผ่น ยังเป็นกระบวนการที่ใช้เวลามาก โดยพนักงานเกือบ 60% คิดว่าหากทำให้งานเหล่านี้เป็นระบบอัตโนมัติได้ จะช่วยประหยัดเวลาได้มากกว่า 6 ชั่วโมงต่อสัปดาห์ [3]
เทคโนโลยี OCR (Optical Character Recognition) ระบบแปลงข้อความเอกสารเป็นข้อความดิจิทัล คือหนึ่งในวิธีการที่สามารถช่วยแก้ปัญหาเหล่านี้ได้ โดยจะเข้าช่วยอ่านข้อมูลจากเอกสารกระดาษหรือไฟล์รูปภาพให้เป็นข้อมูลดิจิทัล ช่วยลดภาระงาน เพิ่มความแม่นยำ และประสิทธิภาพการจัดการข้อมูล การนำเทคโนโลยีนี้มาใช้จึงเป็นก้าวสำคัญสำหรับองค์กรที่ต้องการเพิ่มความสามารถการแข่งขันในยุคดิจิทัล
ความเข้าใจพื้นฐานของ OCR – AI แปลงเอกสารเป็นข้อความ
ด้วยข้อผิดพลาดและความเสี่ยงที่องค์กรต้องแบกรับ ธุรกิจต่าง ๆ จึงเริ่มมองหาวิธีเพิ่มประสิทธิภาพการทำงาน ด้วยการนำระบบอัตโนมัติมาใช้แทนการป้อนข้อมูลด้วยมือ เนื่องจากสามารถช่วยลดความผิดพลาด ประหยัดเวลา และเพิ่มประสิทธิภาพการทำงานได้อย่างมาก
OCR ระบบแปลงข้อความเอกสารเป็นข้อความดิจิทัลคืออะไร?
OCR คือเทคโนโลยีที่ใช้ปัญญาประดิษฐ์แปลงข้อมูลจากเอกสารกระดาษหรือไฟล์ภาพ ให้เป็นข้อความดิจิทัลซึ่งนำข้อมูลที่ได้ไปจัดเก็บ ค้นหาและแก้ไขได้ โดยกระบวนการทำงานของ OCR เริ่มจากการสแกนเอกสาร จากนั้นระบบจะวิเคราะห์และแยกแยะตัวอักษร ตัวเลข และสัญลักษณ์ต่าง ๆ แล้วแปลงเป็นข้อความดิจิทัล
อธิบายให้เห็นภาพแบบง่าย ๆ คือ เหมือนมีคนมานั่งพิมพ์ข้อมูลจากเอกสารให้คุณโดยอัตโนมัตินั่นเอง
ความสำคัญของเทคโนโลยี AI : OCR
การป้อนข้อมูลด้วยมือมักมีข้อจำกัดด้านความแม่นยำ เนื่องจากอาจเกิดความผิดพลาดจากการเสียสมาธิหรือความเหนื่อยล้าได้ง่าย ในทางตรงกันข้าม ระบบ AI : OCR มีความแม่นยำและรวดเร็วกว่า แม้ว่าประสิทธิภาพอาจขึ้นอยู่กับคุณภาพของรูปภาพหรือเอกสารที่ป้อนเข้าไป
OCR ช่วยลดข้อผิดพลาดและเพิ่มความถูกต้องของข้อมูล โดยเฉพาะอย่างยิ่งสำหรับข้อมูลจำนวนมากหรือที่ต้องการความแม่นยำสูง นอกจากนี้ยังเพิ่มความคล่องตัวการจัดการข้อมูล ทำให้องค์กรสามารถเข้าถึงและใช้ประโยชน์จากข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น ด้วยเหตุนี้ OCR จึงเหมาะสมกับงานที่ต้องการความถูกต้องสูงและมีปริมาณข้อมูลมาก
ประโยชน์ของ OCR สำหรับการเพิ่ม ROI
การนำเทคโนโลยี OCR มาใช้ในองค์กรสร้างผลตอบแทนการลงทุน (ROI) ที่สูงขึ้น เนื่องจากช่วยประหยัดเวลาและทรัพยากรสำหรับจัดการเอกสาร ลดความผิดพลาดจากการป้อนข้อมูลด้วยมือ และเพิ่มประสิทธิภาพการเข้าถึงและใช้งานข้อมูล ส่งผลให้องค์กรสามารถตัดสินใจทางธุรกิจได้รวดเร็วและแม่นยำมากขึ้น
-
1.ลดต้นทุนจัดการเอกสาร
-
-
- ลดความจำเป็นการใช้แรงงานมนุษย์เพื่อป้อนข้อมูล
- ประหยัดค่าใช้จ่ายสำหรับจัดเก็บเอกสาร โดย AIIM รายงานว่าองค์กรลดค่าใช้จ่ายจัดเก็บเอกสารได้ถึง 80% เมื่อใช้ระบบ OCR [5]
-
-
เพิ่มประสิทธิภาพการทำงาน
-
-
- พนักงานค้นหาข้อมูลเร็วขึ้น โดยการศึกษาของ IDC พบว่าพนักงานประหยัดเวลาค้นหาข้อมูลได้ถึง 30% เมื่อใช้ระบบ OCR [6]
- แชร์ข้อมูลและไฟล์ต่าง ๆ ภายในองค์กรได้สะดวกขึ้น ทำให้การทำงานร่วมกันของพนักงานแต่ละทีมมีประสิทธิภาพมากขึ้น
-
-
การเพิ่มรายได้และโอกาสการแข่งขันทางธุรกิจ
-
- ปรับปรุงประสบการณ์ลูกค้าด้วยการให้บริการที่รวดเร็วและแม่นยำมากขึ้น
- เพิ่มศักยภาพการวิเคราะห์ข้อมูลเชิงลึก McKinsey รายงานว่าองค์กรที่ใช้ข้อมูลอย่างมีประสิทธิภาพมีโอกาสเพิ่มผลกำไรได้มากกว่า 60% เมื่อเทียบกับคู่แข่ง [7]
ตัวอย่างกลุ่มธุรกิจที่ประสบความสำเร็จจากการใช้ OCR
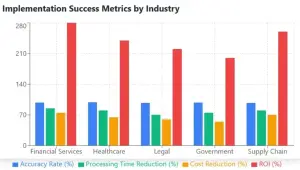
กราฟแสดงความสำเร็จของการใช้ OCR แต่ละกลุ่มธุรกิจ [8]
-
OCR ในกลุ่มธุรกิจการเงิน / การธนาคาร – การประมวลผลเอกสารการเงินและการจัดการใบแจ้งหนี้
-
-
- ช่วยดึงข้อมูลสำคัญจากใบแจ้งหนี้ แบบฟอร์มธนาคาร บัตรประชาชน สมุดเล่มทะเบียนรถ สมุดบัญชีธนาคาร สลิปเงินเดือนโดยอัตโนมัติ
- ลดเวลาประมวลผลจาก 15 นาทีต่อฉบับ เหลือน้อยกว่า 1 นาที [8]
- มีความแม่นยำสูงกว่า 98% สำหรับเอกสารมาตรฐาน [8]
-
-
OCR ในกลุ่มการแพทย์ / โรงพยาบาล -การจัดการบันทึกทางการแพทย์และเอกสารผู้ป่วย
-
-
- ช่วยแปลงบันทึกทางการแพทย์จากเป็นข้อมูลดิจิทัลอย่างมีประสิทธิภาพ
- รองรับเอกสารหลากหลายประเภท เช่น ประวัติผู้ป่วย ผลแล็บ ใบสั่งยา
- ความแม่นยำสูงกว่า 99% สำหรับแบบฟอร์มทางการแพทย์ที่มีโครงสร้าง [8]
-
-
OCR ในกลุ่มกฎหมาย – เอกสารทางกฎหมายและการจัดการสัญญา
-
-
- ช่วยประมวลผลสัญญา เอกสารศาล และจดหมายทางกฎหมาย
- ลดเวลาการตรวจสอบเอกสารลงได้ถึง 70% [8]
- สามารถระบุคำศัพท์ทางกฎหมาย สกัดข้อความสำคัญ และระบุเงื่อนไขสำคัญได้
-
-
OCR ในกลุ่มหน่วยงานรัฐ – การประมวลผลเอกสารของภาครัฐและหน่วยงานราชการ
-
-
- ช่วยประมวลผลเอกสารประชาชน การยื่นภาษี และบันทึกทางราชการ
- รองรับหลายภาษาและรูปแบบเอกสาร
- รักษาความปลอดภัยและเป็นไปตามข้อกำหนดทางกฎหมาย
-
-
OCR ในกลุ่มธุรกิจ Supply Chain – เอกสารด้าน Supply Chain และโลจิสติกส์
-
- ช่วยประมวลผลเอกสารการขนส่ง ใบขนและใบรับสินค้า และบันทึกสินค้าคงคลัง
- ลดเวลาประมวลผลลงได้ถึง 80% เมื่อเทียบกับการทำด้วยมือ [8]
- ปรับปรุงความสามารถการติดตามและตรวจสอบสินค้า
ทดลองใช้ระบบ AI: OCR ก่อนตัดสินใจ

ฟรี! ทดลองใช้ Demo OCR by WordSense
OCR by WordSense บริษัทในเครือ Looloo Technology หนึ่งในผู้นำตลาด OCR ไทยในปัจจุบัน โดดเด่นด้วยความแม่นยำสูงสำหรับการอ่านลายมือภาษาไทย “OCR Handwriting” ที่แปลงลายมือภาษาไทยเป็นข้อความดิจิทัลได้อย่างแม่นยำ
Average Accuracy Rate ตั้งต้นของ OCR by WordSense
- 92% OCR Handwriting แปลงลายมือภาษาไทยเป็นข้อความดิจิทัล
- 95% OCR Typed แปลงตัวพิมพ์ภาษาไทยเป็นข้อความดิจิทัล
Tips : ตัวเลข Average Accuracy Rate ตั้งต้น หมายความว่า ยิ่งคุณใช้งาน OCR ของเราเท่าไร ระบบก็ยิ่งเรียนรู้และพัฒนาขึ้นเรื่อย ๆ
WordSense บริษัทในเครือ Looloo Technology เรามุ่งมั่นที่จะทำให้ข้อมูลเข้าถึงได้ง่าย สะดวก และพร้อมใช้งานทันที ภายใต้แนวคิด “Human Data Made Ready
ฟรี! ทดลองใช้ Demo OCR https://wordsense-ocr-demo.loolootech.com
ฟรี! ปรึกษากับผู้เชี่ยวชาญของเรา 3 ชั่วโมง! ติดต่อ WordSense วันนี้ เพื่อธุรกิจที่ Smart และแม่นยำขึ้น
ติดต่อ: อีเมล: [email protected] หรือ โทรศัพท์: 02 028 7557
รายละเอียดเพิ่มเติม https://loolootech.com/wordsense-ocr/
บทสรุปการนำ OCR มาใช้เพื่อเพิ่ม ROI ในองค์กร
การนำ OCR มาใช้ในองค์กรไม่เพียงแต่ช่วยเพิ่ม ROI แต่ยังเป็นก้าวสำคัญสำหรับการยกระดับมาตรฐานการทำงานสู่ยุคดิจิทัลอย่างเต็มรูปแบบ ในโลกธุรกิจที่การแข่งขันทวีความรุนแรง การปรับตัวและนำเทคโนโลยีมาใช้อย่างชาญฉลาดจึงเป็นกุญแจสำคัญสู่ความสำเร็จ
ถึงเวลาแล้วที่องค์กรของคุณจะก้าวสู่การเปลี่ยนแปลงครั้งสำคัญ ด้วยการนำ OCR มาใช้เพื่อปลดล็อกศักยภาพการจัดการข้อมูล เพิ่มประสิทธิภาพการทำงาน และสร้างความได้เปรียบในการแข่งขัน อย่าปล่อยให้โอกาสพัฒนาธุรกิจของคุณหลุดลอยไป เริ่มต้นการเดินทางสู่การเปลี่ยนแปลงทางดิจิทัลด้วย OCR วันนี้ เพื่อก้าวสู่อนาคตที่สดใสกว่าของธุรกิจคุณ
สนใจรับคำปรึกษาฟรี 3 ชั่วโมง ติดต่อเราวันนี้ โทร. 02-028-7557
ฟรี! ทดลองใช้ Demo OCR by WordSense : wordsense-ocr-demo.loolootech.com
แหล่งข้อมูลอ้างอิง
[1] https://www.businesswire.com/news/home/20190228005139/en/report-Manual-Processes-Limiting-Value-of-Data-in-Manufacturing
[2] https://www.gartner.com/smarterwithgartner/how-to-create-a-business-case-for-data-quality-improvement#:~:text=Poor%20data%20quality%20destroys%20business%20value.%20Recent%20Gartner,a%20challenge%20faced%20by%20organizations%20of%20all%20sizes
[3] https://www.smartsheet.com/content-center/product-news/automation/workers-waste-quarter-work-week-manual-repetitive-tasks
[4] https://www.docuclipper.com/blog/ocr-data-entry/#:~:text=OCR%20Data%20Entry%3A%20Highly%20accurate,be%20as%20high%20as%204%25.
[5] AIIM: https://info.aiim.org/state-of-the-industry-intelligent-information-management
[6] IDC: https://www.idc.com/getdoc.jsp?containerId=prUS45119219
[7] McKinsey: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-data-driven-enterprise-of-2025
[8] https://artificio.ai/blog/top-5-use-cases-of-ocr-technology-in-streamlining-business-processes
—————————————–
Looloo Technology is a leading AI consulting company, renowned for delivering cutting-edge and customized AI and Data Analytics solutions, with expertise in predictive analytics, natural language processing (NLP), intelligent document processing (IDP), and automatic speech recognition (ASR), Our application of design thinking methodology ensures a deep understanding of our clients, complemented by a strategic consulting approach to identify areas for maximal impact. Emphasizing rigorous user testing, we fine-tune our solutions to precisely meet the users needs.
Our team is a collective of exceptional individuals with global experience handpicked from top institutions. Their relentless pursuit of excellence and commitment to innovation is what sets us apart and help bring our clients substantial growth and profitability.
🌐 Website : www.loolootech.com
📱 Facebook : Looloo Technology
📸 Instagram : loolootech
![]() TikTok: @loolootech
TikTok: @loolootech


